DeepRails
DeepRails delivers real-time AI guardrails to detect and correct LLM hallucinations, ensuring accuracy before user.
Visit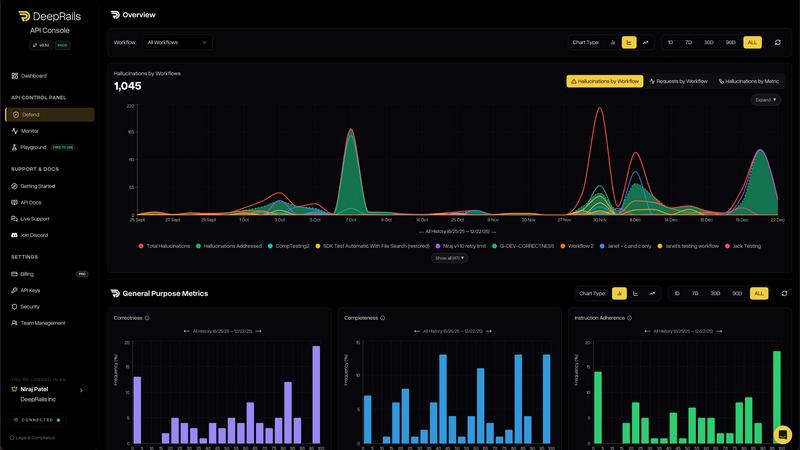
About DeepRails
DeepRails is an advanced AI reliability and guardrails platform meticulously designed for developers and engineering teams engaged in building production-ready AI systems. Its primary objective is to serve as the ultimate safeguard against LLM hallucinations, empowering teams to deploy trustworthy AI solutions by not only identifying but also effectively rectifying erroneous outputs. By addressing the critical challenges posed by model hallucinations and factual inaccuracies, DeepRails significantly enhances the real-world adoption of AI technologies. The platform offers a model-agnostic suite that integrates seamlessly into contemporary development pipelines, providing real-time evaluations of AI outputs for their factual accuracy, grounding, and reasoning consistency. What sets DeepRails apart is its proactive approach, which goes beyond simple detection to include automated remediation workflows, enabling teams to customize evaluation metrics that align with their specific business objectives. With essential features like human-in-the-loop feedback and a comprehensive analytics dashboard, DeepRails ensures the continuous enhancement of model performance, instilling confidence and control in engineering teams to deploy AI at scale without sacrificing reliability or accuracy.
Features of DeepRails
Ultra-Accurate Hallucination Detection
DeepRails employs sophisticated algorithms to identify LLM hallucinations with exceptional accuracy. This feature ensures that any erroneous or misleading information generated by the AI is flagged and addressed before it reaches end users, enhancing the overall reliability of AI outputs.
Automated Remediation Workflows
Going beyond detection, DeepRails offers automated remediation through workflows like FixIt and ReGen. These tools allow teams to immediately correct identified issues in AI outputs, ensuring that the information provided is not only accurate but also adheres to the desired quality standards.
Customizable Evaluation Metrics
Users can configure guardrail metrics and hallucination thresholds tailored to their specific needs. This flexibility enables businesses to align the evaluation of AI output quality with their unique operational goals, ensuring that every deployment meets rigorous standards.
Comprehensive Analytics Dashboard
The DeepRails analytics console provides a detailed overview of performance metrics, improvement chains, and audit logs. This feature allows teams to track the effectiveness of their AI systems over time, facilitating data-driven decision-making and continuous improvement in model behavior.
Use Cases of DeepRails
Legal Document Review
In legal applications, DeepRails can verify the accuracy of AI-generated citations and case law references, ensuring that attorneys rely on correct and relevant information when preparing for court cases, thus minimizing legal risks.
Financial Advisory Services
DeepRails enhances the reliability of AI outputs in financial advisory by ensuring that recommendations are factually accurate and comprehensive, allowing financial professionals to provide clients with trustworthy advice and insights.
Healthcare Applications
For healthcare systems utilizing AI, DeepRails ensures that patient care recommendations and drug interaction information are accurate and safe. This feature is vital for maintaining high standards of patient safety and clinical effectiveness.
Educational Platforms
In educational settings, DeepRails can assess the accuracy and relevance of AI-generated content used for instructional purposes. This capability ensures that learners receive correct information and enhances the overall quality of educational materials.
Frequently Asked Questions
How does DeepRails detect LLM hallucinations?
DeepRails uses advanced algorithms and customizable metrics to accurately detect hallucinations in AI outputs. This ensures that any misleading or incorrect information is flagged before reaching users.
Can I customize the evaluation metrics in DeepRails?
Yes, DeepRails allows users to configure guardrail metrics and hallucination thresholds tailored to their specific business objectives, ensuring the evaluation process aligns with operational needs.
What types of automated remediation does DeepRails offer?
DeepRails provides automated remediation workflows like FixIt and ReGen, which allow teams to quickly correct any identified issues in AI outputs, ensuring high-quality information delivery.
How can I track the performance of my AI models with DeepRails?
DeepRails features a comprehensive analytics dashboard that tracks performance metrics, improvement chains, and audit logs, enabling teams to monitor and enhance the effectiveness of their AI models over time.