Friendli Engine
About Friendli Engine
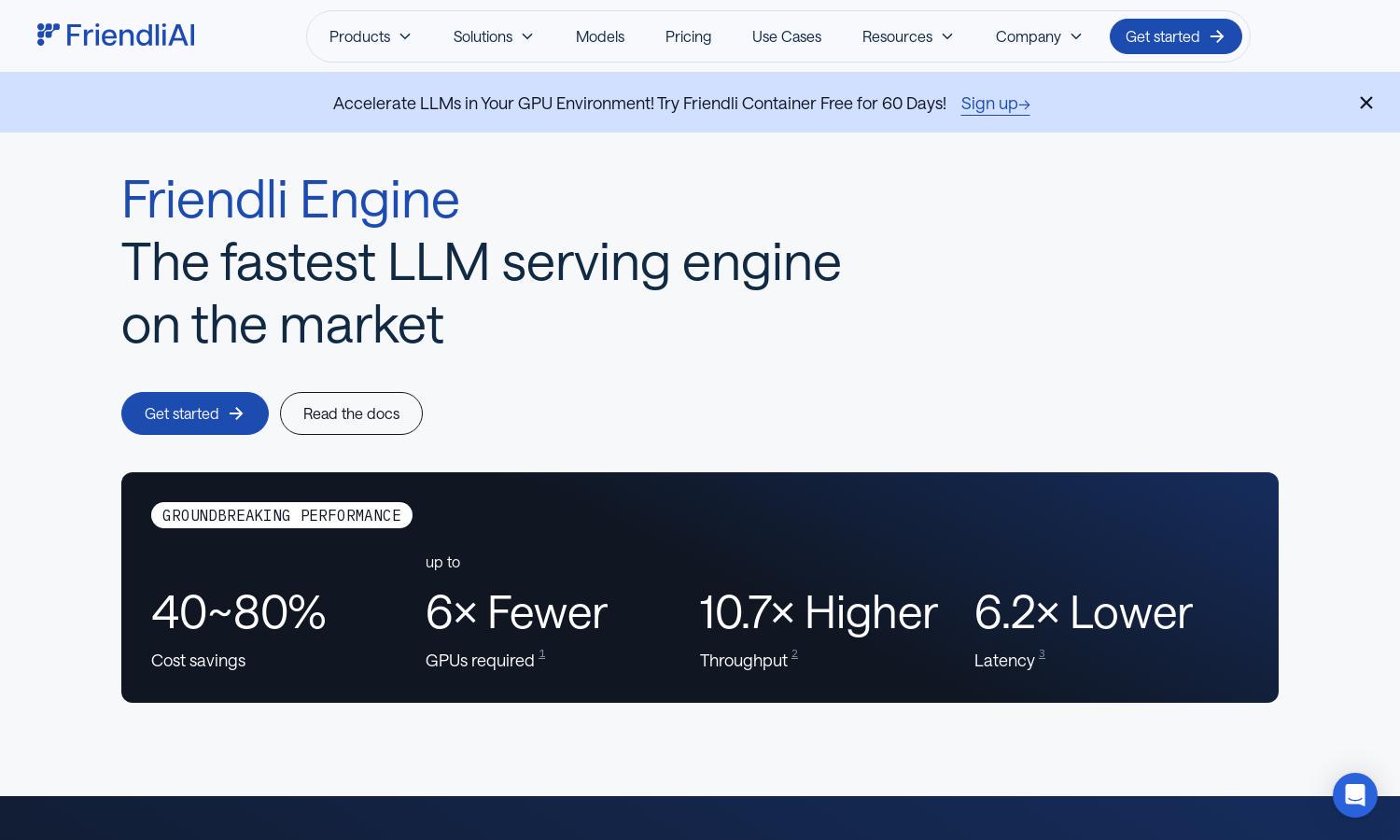
Friendli Engine is a cutting-edge platform designed for businesses and developers looking to deploy generative AI models efficiently. Featuring groundbreaking technology like iteration batching and Friendli TCache, it ensures rapid LLM inference and significant cost savings, making AI more accessible and useful for various applications.
Friendli Engine offers flexible pricing plans for users, from free trials to premium tiers. Each subscription provides enhanced features, including dedicated endpoints for high-performance needs. Upgrading to premium plans unlocks more extensive model support and faster inference capabilities, ensuring value-packed options for all users.
The user interface of Friendli Engine is intuitive, creating a seamless browsing experience. Its streamlined layout allows users to easily navigate various features, such as model deployment and performance analytics, enhancing usability. Key functionalities are easily accessible, ensuring that both beginners and experts can effectively utilize Friendli Engine.
How Friendli Engine works
Users start by signing up for Friendli Engine and selecting their preferred deployment method, such as Dedicated Endpoints or Container services. Once onboarded, they can upload models and configure settings through a user-friendly dashboard. With real-time performance analytics and optimization features, users enjoy streamlined interactions that enhance efficiency and affordability on their AI projects.
Key Features for Friendli Engine
Iteration Batching Technology
Friendli Engine's iteration batching technology significantly boosts LLM inference throughput while maintaining low latency. This innovative feature allows concurrent requests to be handled efficiently, offering users high performance and cost savings. Friendli Engine is tailored to meet the demands of rapid AI processing without sacrificing quality.
Multi-LoRA Model Support
Friendli Engine distinguishes itself with multi-LoRA model support, enabling users to fine-tune multiple models on a single GPU. This functionality makes LLM customization accessible and efficient, allowing developers to deploy a range of models simultaneously while optimizing resource usage. Experience enhanced flexibility with Friendli Engine.
Friendli TCache
Friendli TCache is a unique feature of Friendli Engine that intelligently stores frequently used computational results. By reusing these cached outputs, it substantially lowers GPU workload and optimizes Time to First Token (TTFT), ensuring faster response times and enhanced performance for users engaging with generative AI models.