WebPageSnap - Professional Web Scraper API
WebPageSnap is a high-performance API that scrapes and structures web data for seamless integration into any tech stack.
Visit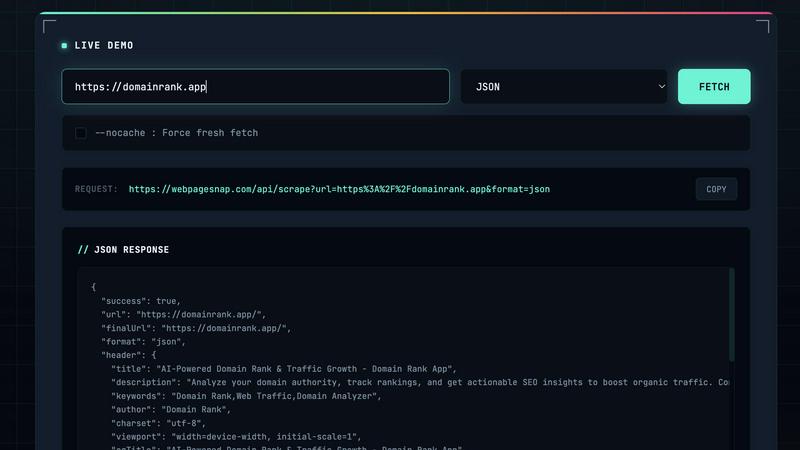
About WebPageSnap - Professional Web Scraper API
WebPageSnap is an enterprise-grade web scraping API engineered for developers, data engineers, and businesses that demand high-performance, reliable data extraction from public web pages. Built on the Cloudflare Workers serverless platform, it transforms the complex task of web scraping into a simple, fast, and scalable API call. The core value proposition lies in its global edge network architecture, which delivers cached content in under 50 milliseconds, making it an ideal backend for applications requiring near real-time data, such as dynamic dashboards, price monitoring tools, or content aggregation services. It automatically parses and returns structured metadata—including titles, descriptions, Open Graph, and Twitter Card tags—alongside the raw HTML body, providing flexibility for both automated data pipelines and direct analysis. With a generous free tier of 100,000 requests per day and seamless integration capabilities via a clean REST API, WebPageSnap is designed to be a foundational tech-stack component, eliminating the overhead of managing proxies, browsers, or rate-limiting logic.
Features of WebPageSnap - Professional Web Scraper API
Global Edge Network Deployment
Deployed across 200+ Cloudflare edge nodes worldwide, the API ensures the lowest possible latency by routing requests to the nearest geographical point of presence. This architecture guarantees consistent sub-50ms response times for cached content, providing a performance benchmark essential for user-facing applications and high-frequency data jobs where speed is a critical integration factor.
Intelligent KV Storage Caching
The API leverages Cloudflare's KV storage for intelligent caching with a seven-day Time-To-Live (TTL), achieving a cache hit rate of over 95%. This feature dramatically reduces load on target websites and accelerates response times for frequently requested URLs. Developers can bypass the cache using the nocache parameter for force-fetching fresh content, offering precise control over data freshness within their workflows.
Multi-Format Output (JSON & HTML)
WebPageSnap delivers extracted content in two developer-friendly formats. The default JSON output provides pre-parsed, structured metadata for immediate use in applications. The alternative HTML format returns the fully rendered page body, ideal for scenarios requiring custom parsing or full-page archival. This dual-output system ensures compatibility with a wide range of downstream processing tools and databases.
Advanced Anti-Bot Bypass & Redirect Handling
The API employs realistic browser simulation to navigate and extract content from JavaScript-heavy modern websites, automatically following client-side redirects to capture the final page content. This anti-bot bypass capability ensures reliable data extraction from complex web applications, reducing the failure rate commonly associated with simple HTTP-based scrapers and simplifying integration into robust data pipelines.
Use Cases of WebPageSnap - Professional Web Scraper API
Real-Time Market & Price Intelligence
Integrate the API into monitoring systems to track competitor pricing, product availability, and promotional offers across multiple e-commerce domains. The sub-50ms cached responses enable the construction of live price comparison engines and alert systems that can react to market changes instantly, providing a competitive edge in dynamic retail sectors.
Content Aggregation & News Monitoring
Power content curation platforms, news aggregators, or research tools by programmatically fetching articles, blog posts, and announcements from a predefined list of sources. The automatic extraction of metadata (title, description, OG image) simplifies the process of creating structured content feeds and databases without manual intervention.
SEO & Website Audit Automation
Automate the collection of on-page SEO elements from large site inventories. Developers can build tools that batch-process URLs to extract meta tags, headings, and content for analysis, tracking changes over time or verifying implementation across thousands of pages, seamlessly integrating this data into existing SEO software stacks.
AI Training Data & LLM Context Enrichment
Efficiently gather and sanitize web-based text and data to create high-quality datasets for training machine learning models. Furthermore, the API can be integrated into AI agent workflows (via the Claude Code Skill) to fetch live webpage context, allowing Large Language Models to access and reason about current web content in real-time.
Frequently Asked Questions
What is a web scraper API and how does WebPageSnap differ?
A web scraper API is a service that programmatically extracts content from websites, handling the complexities of HTTP requests, parsing, and session management. WebPageSnap differentiates itself by being built on a global edge network (Cloudflare Workers), which provides exceptional speed and reliability. It offers enterprise-grade features like intelligent caching, automatic JavaScript rendering, and structured JSON output out-of-the-box, making it more of a scalable infrastructure component than a simple extraction tool.
How does this web scraper API handle JavaScript-rendered pages?
Our API simulates real browser behavior to execute JavaScript and automatically follow client-side redirects, ensuring you receive the fully rendered HTML content from the final destination page. This capability allows it to reliably scrape modern, JavaScript-heavy web applications (like those built with React, Vue.js, or Angular) without requiring you to manage a headless browser environment.
Is the web scraper API free to use?
Yes, WebPageSnap offers a generous free tier allowing for 100,000 requests per day. This makes it highly accessible for prototyping, low-volume projects, and initial integration phases. For higher volume needs, refer to our website for detailed information on scalable paid plans designed for enterprise workloads.
How can I integrate WebPageSnap with AI assistants like Claude?
We provide a dedicated Claude Code Skill that, once installed, allows Claude Code to automatically call the WebPageSnap API when you ask it to fetch or scrape a webpage. This enables seamless interaction where you can simply prompt, "What's on this page: [URL]" and Claude will retrieve and analyze the live content using our API, bridging the gap between AI reasoning and real-time web data.
Explore more in this category:
Similar to WebPageSnap - Professional Web Scraper API
TrafficClaw transforms your SEO and analytics data into actionable insights through natural conversation, driving traffic growth effortlessly.
LinkFinder AI enriches your data instantly with accurate company details from multiple trusted sources.
BlitzAPI provides scalable B2B data through powerful APIs, empowering your growth team's strategies with validated.
LLMWise offers a single API to seamlessly access and compare multiple AI models, charging only for what you use.
AntiTemp is an API that verifies emails for Product, Growth, and Risk teams, ensuring accurate detection and governance.
Unlock powerful AI capabilities with My Deepseek API for cost-effective, scalable, and production-ready solutions.
CCAPI is your all-in-one AI API gateway, providing seamless access to multiple AI models for text, image, audio, and.
Renderly automates video production at scale, enabling thousands of personalized videos through a powerful API and.